✨ TL;DR
VAEs are generative models that learn probability distributions to create new data variations. Unlike GANs, they offer stable training and interpretable latent spaces, making them ideal for research and practical applications.
🔹 Introduction
Imagine if your computer could not only compress an image but also dream up entirely new ones that look realistic. That's exactly what Variational Autoencoders (VAEs) do.
VAEs are a class of generative models—algorithms that can create new data similar to what they've learned. While Generative Adversarial Networks (GANs) often steal the spotlight, VAEs are more mathematically elegant and stable to train.
🔹 What is a Variational Autoencoder?
At its core, a VAE is an autoencoder with a twist:
- A standard autoencoder learns to compress and reconstruct data.
- A VAE learns probability distributions, allowing it to generate new samples rather than just reconstruct inputs.
📌 Think of it like this:
- An autoencoder makes a photocopy of your data.
- A VAE learns the style of your data, so it can produce new variations.
🔹 How Does a VAE Work?
1. Encoder (Compresses Input)
- Takes input data (e.g., an image).
- Outputs two values: mean (μ) and variance (σ²).
- These define a distribution in a hidden space (latent space).
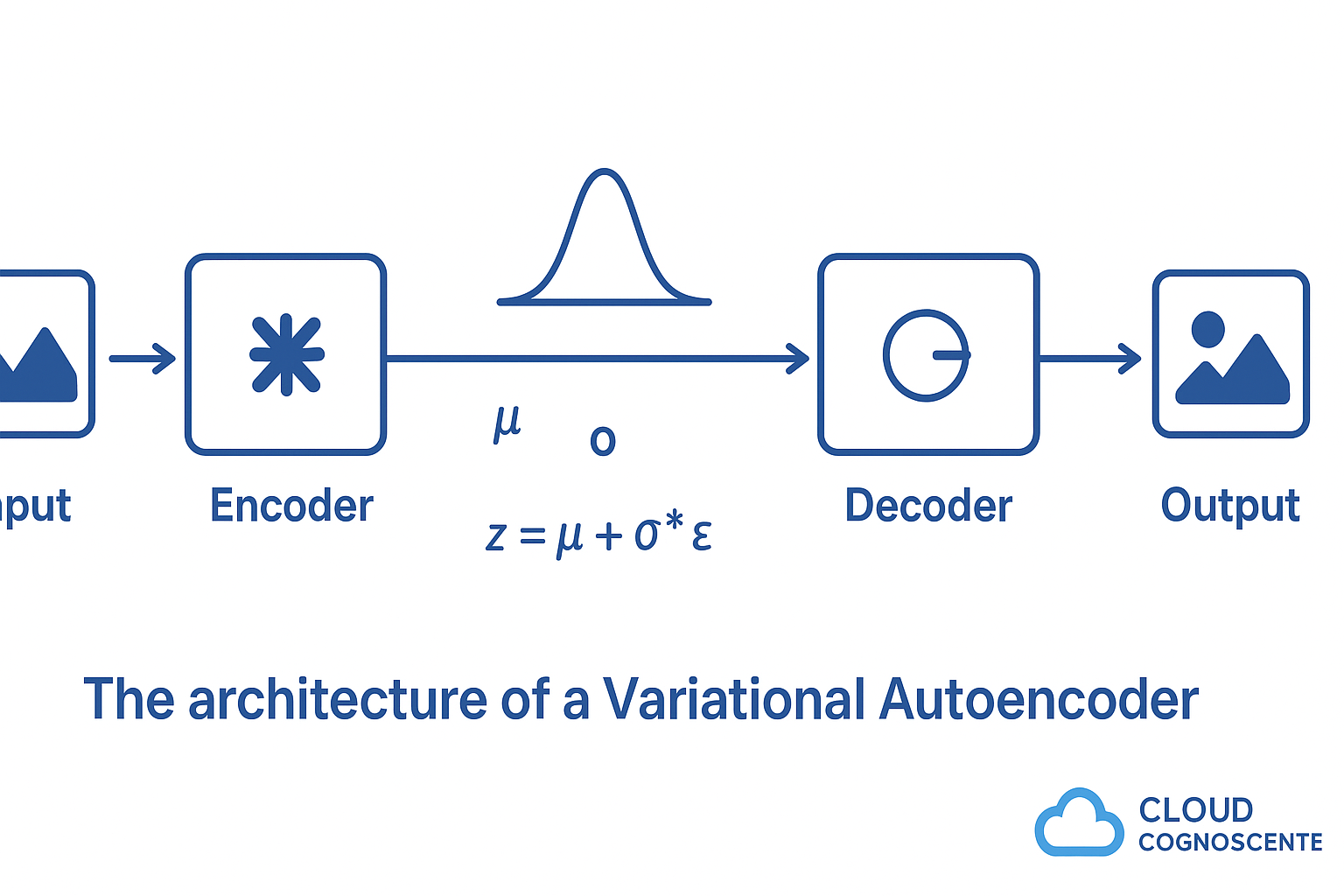
Figure 1: VAE Encoder architecture showing how input data is compressed into mean and variance parameters
2. Latent Sampling (The Trick)
- Instead of a fixed code, the VAE samples from this distribution.
- Formula: z = μ + σ * ε, where ε is random noise.
- This "reparameterization trick" makes training possible.
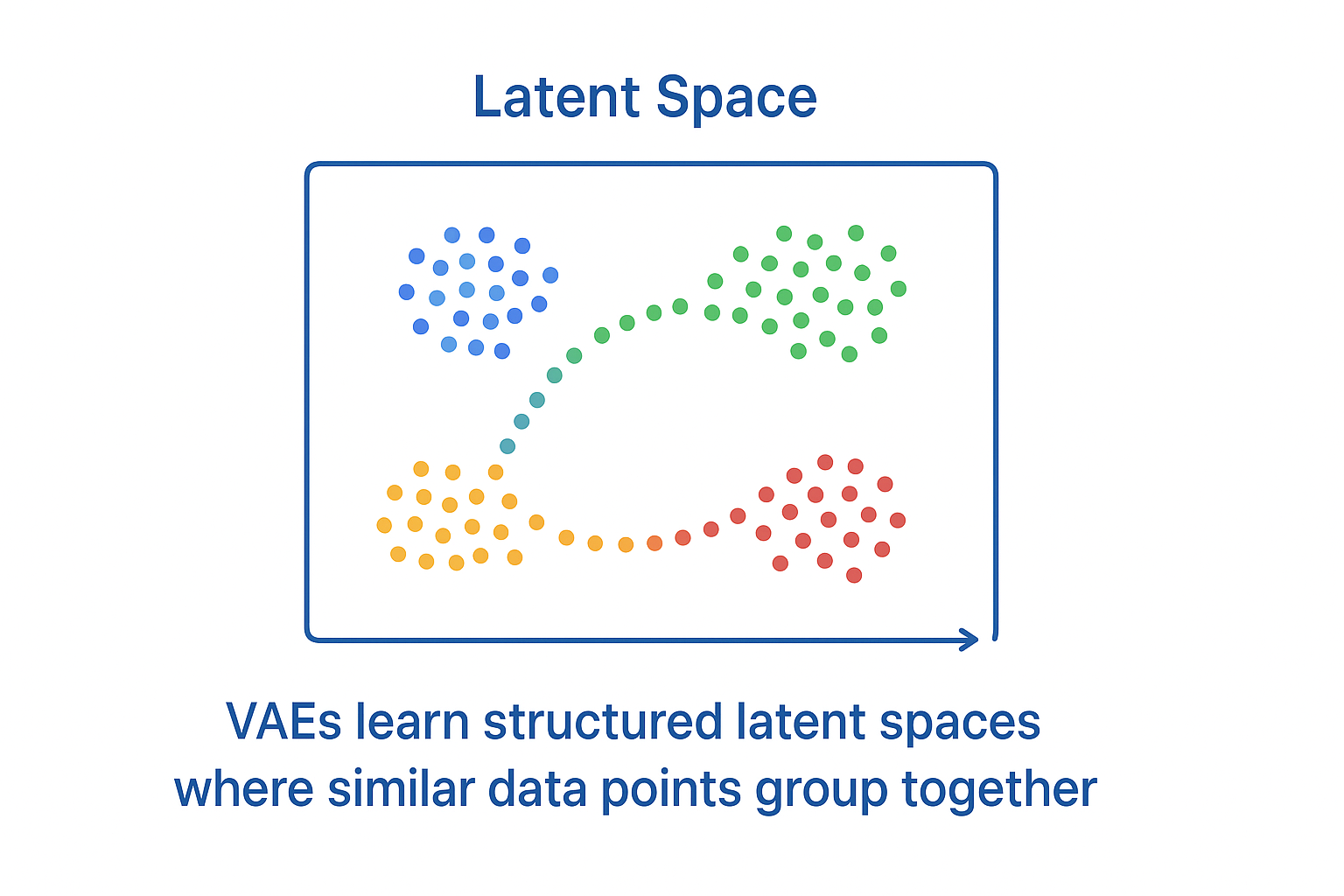
Figure 2: The reparameterization trick that enables backpropagation through stochastic sampling
3. Decoder (Reconstructs or Generates)
- Takes the sampled latent code z.
- Reconstructs the original data—or generates entirely new data.
🔹 The VAE Loss Function
The VAE optimizes two objectives:
- Reconstruction Loss → ensures outputs look like inputs.
- KL Divergence Loss → ensures the learned distribution stays close to a standard Gaussian.
Mathematically, it balances fidelity (how well it reconstructs) with creativity (how well it generalizes).
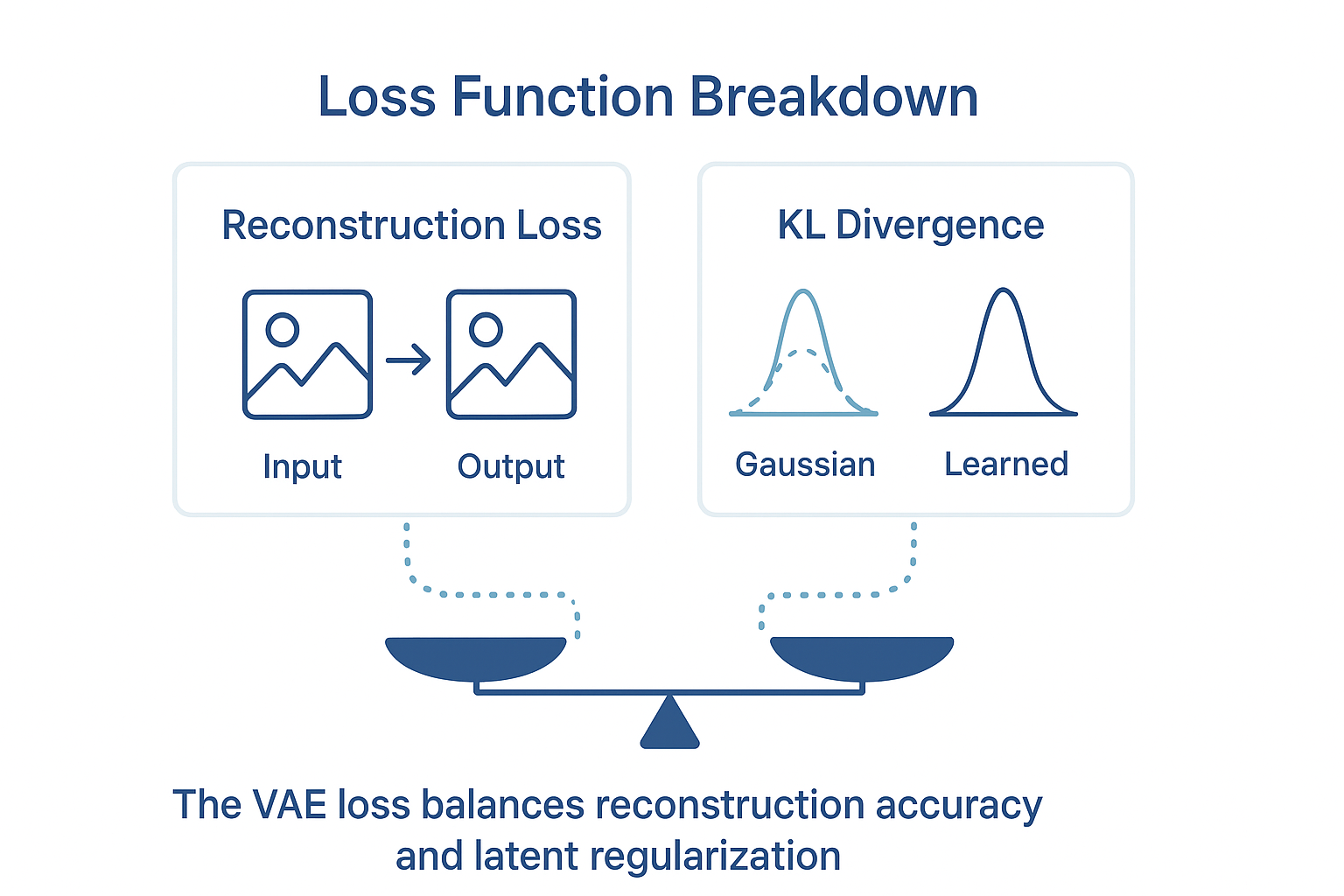
Figure 3: VAE loss function showing the balance between reconstruction loss and KL divergence
🔹 Why VAEs are Important
- Stable Training → Unlike GANs, VAEs don't need adversarial battles.
- Interpretability → Latent space often encodes meaningful features (e.g., in faces: smile, hair color).
- Generative Power → Can create novel examples, not just reconstructions.
🔹 Real-World Applications
VAEs are widely used in research and industry:
- 🎨 Art & Creativity → Generating new artistic styles.
- 🖼 Image Enhancement → Denoising, super-resolution.
- 🧬 Healthcare → Drug discovery, molecule generation.
- 📊 Anomaly Detection → Identifying fraud or rare events.
- 🎤 Speech & NLP → Generating realistic audio or text embeddings.
Figure 4: Various applications of VAEs across different domains and industries
🔹 Comparison: VAE vs GAN
| Feature | VAE | GAN |
|---|---|---|
| Training | Stable, single loss | Adversarial, tricky to balance |
| Output | Blurry but realistic | Sharp, high-quality |
| Latent space | Structured, interpretable | Harder to interpret |
| Use cases | Research, anomaly detection, semi-supervised learning | Photorealistic image synthesis |
🔹 Key Takeaway
Variational Autoencoders may not produce the sharpest images like GANs, but they shine in stability, mathematical grounding, and interpretability. They are a cornerstone in the evolution of generative AI.
📌 "VAEs don't just copy data—they learn its essence, opening the door to endless variations."